
这是一个创建于 2752 天前的主题,其中的信息可能已经有所发展或是发生改变。
在上一篇普及过Spark的相关概念之后,让我们继续深入研究它的核心结构以及好用的 API ,本篇视频内容丰富,机( fan )智( qiang )的小伙伴不容错过。
前篇传送门:全方位掌握 Apache Spark 2.0 七步走(一)
三、 Apache Spark 的核心结构
为了更好地理解 Spark 的各个组件是如何交互的,在细节上抓住 Spark 的核心结构是很有必要的。所有关键词和概念在解释后才会变得生动形象,这篇 Spark Summit 大会上的培训视频对于你更快开启 Spark 之旅很有帮助:
视频链接: https://youtu.be/7ooZ4S7Ay6Y
四、 DataFrames, Datasets 以及 Spark SQL
在步骤 3 中,你已经了解到弹性分布式数据集( RDDs )——它们构成了 Spark 的核心数据抽象概念,是其他所有更高层次数据抽象和 API 、包括 DataFrame 和数据集的基础。
在 Spark2.0 ,在 RDDs 之上的 DataFrame 和数据集形成了核心的高层和结构化的分布式数据抽象。 DataFrame 在 Spark 里被叫做数据列( data column ),它们可以执行组织数据的计划,以及数据处理或者描述运算、发布查询。数据集更进一步,提供了一个严格的编译时类型的安全保障,所以特定类型的错误在编译时就会被发现,而不是在运行时。
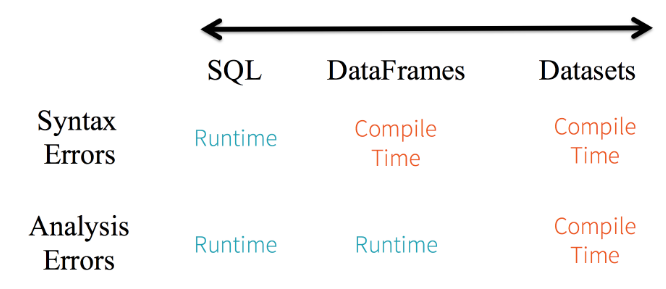
凭借数据结构和数据类型, Spark 可以理解你将如何进行描述运算,哪些指定类型的列或者特定名称的字段将会访问你的数据,以及你将使用哪些特定操作的作用域。然后, Spark 将会通过 Spark 2.0 ’ s Catalyst optimizer 优化你的代码,通过 Project Tungsten 生成高效的字节代码。
DataFrame 和数据集为多种高级编程语言提供了 API ,让你的代码更易读,以及支持高阶函数比如 filter, sum, count, avg, min, max 等等。不管你用 Spark SQL 还是 Python 、 Java 、 Scala 或者 R 来表达你的计算指令,底层的代码生成是完全一致的,因为所有的执行的计划都是通过同一 Catalyst 优化器。
例如, Scala 的作用域专用代码或者它 SQL 里对应的相关查询会生成完全相同的代码。比如下方会有一个数据集 Scala 项目叫做 Person ,以及一个 SQL 表格“ Person ”。
// a dataset object Person with field names fname, lname, age, weight
// access using object notation
val seniorDS = peopleDS.filter(p=>p.age > 55)
// a dataframe with structure with named columns fname, lname, age, weight
// access using col name notation
Val seniorDF = peopleDF.where(peopleDF("age") > 55)
// equivalent Spark SQL code
val seniorDF = spark.sql("SELECT age from person where age > 35")
为什么 Spark 结构化数据很重要,为什么 DataFrame 、数据集、 Spark SQL 提供了一个高效的 Spark 编码方式,如果你希望了解这些,可以通过链接( https://youtu.be/1a4pgYzeFwE )的视频寻找答案。
五、 GraphFrame 的图形处理
尽管 Spark 有一个通用的基于 RDD 的图形处理库 GraphX ,可以优化分布式计算以及支持图形算法,它仍有一些挑战——没有 Java 和 Python API ,基于低层的 RDD API 。由于这些问题,它不能通过 Project Tungsten 和 Catalyst Optimizer 享受到最近引入的性能优化。
相比之下,基于 DataFrame 的图处理库 GraphFrames 解决了所有问题:它提供了一个类似于 GraphX 的库但是有着更高的层级,更易读和可读的 API ,支持 Java, Scala 和 Python ;可以保存和下载图形;利用了 Spark2.0 的底层性能和查询的优化。此外,它集成了 GraphX 。这意味着你可以无缝地将图处理库 GraphFrames 转换成等效的 GraphX 表示。
在下图中,这些城市有各个机场代号,所有顶点可以表示成 DataFrame 的排;同样地,所有边也可以看做 DataFrame 的排,它们有着各自的名字和类型的列。总的来说,这些 DataFrame 的顶点和边构成了一个图处理库 GraphFrames 。
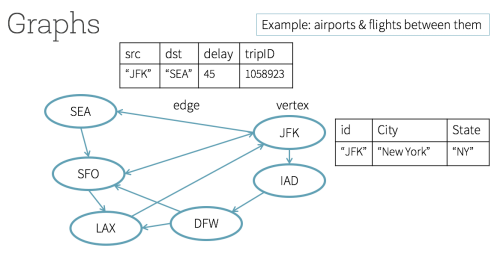
// create a Vertices DataFrame
val vertices = spark.createDataFrame(List(("JFK", "New York", "NY"))).toDF("id", "city", "state")
// create a Edges DataFrame
val edges = spark.createDataFrame(List(("JFK", "SEA", 45, 1058923))).toDF("src", "dst", "delay", "tripID")
// create a GraphFrame and use its APIs
val airportGF = GraphFrame(vertices, edges)
// filter all vertices from the GraphFrame with delays greater an 30 mins
val delayDF = airportGF.edges.filter("delay > 30")
// Using PageRank algorithm, determine the Airport ranking of importance
val pageRanksGF = airportGF.pageRank.resetProbability(0.15).maxIter(5).run()
display(pageRanksGF.vertices.orderBy(desc("pagerank")))
使用 GraphFrame 可以表达三种强大的查询。首先是简单的 SQL 类型的关于点和边的查询,比如怎么样的路线可能会导致重大延迟。第二,图形类型查询,比如有多少顶点传入有多少边传出。第三,主题查询,通过提供一个结构化的模型或者路径的顶点和边,找到在图形中的数据集的模型。
此外,图处理库 GraphFrames 可以很轻松地支持 GraphX 所有图形算法。例如,使用 PageRank 找到所有重要的点,或者决定从起点到目的地的最短路径,或者执行一个广度优先搜索(BFS),或者为探索联络关系确定强联系的点。
在网络研讨会中( http://go.databricks.com/graphframes-dataframe-based-graphs-for-apache-spark )中, Spark 的社区贡献者 Joseph Bradley 给大家介绍了使用图处理库 GraphFrames 进行图像处理的动机和易用性,以及基于 DataFrame 的 API 的好处。作为研讨会的一部分,你也将了解到使用图处理库 GraphFrames 的便捷,以及上述所有类型的查询和算法。
Apache Spark 2.0 和许多 Spark 的组件,包括机器学习 MLlib 和 Streaming ,因为性能提升、易用性和高层次的抽象及结构,越来越倾向于提供等效的 DataFrame API 。在必要或者适合的用例中,你可以选择使用图处理库 GraphFrames 来代替 GraphX 。下图是一个 GraphX 和图处理库 GraphFrames 之间简洁的总结和比较。
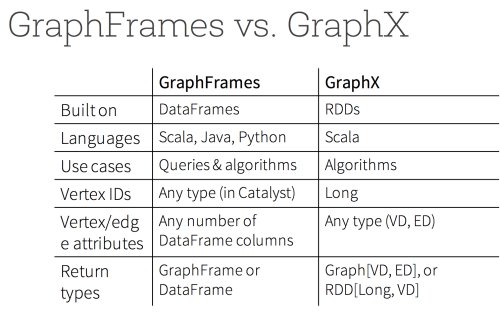
图处理库 GraphFrames 必会发展得越来越快。新版本的 GraphFrame 将作为 Spark 的一个包和 Spark2.0 兼容。
作者: Jules S. Damji & Sameer Farooqui, Databricks. 文章来源: http://www.kdnuggets.com/2016/09/7-steps-mastering-apache-spark.html
目前尚无回复