

这是一个创建于 2580 天前的主题,其中的信息可能已经有所发展或是发生改变。
作者介绍: Ben Maurer 是 Facebook 的网络基础团队的技术领先者,主要负责整个 Facebook 面向用户产品的性能和可靠性。 Ben 于 2010 年正式加入 Facebook ,基础设施团队的成员。在加入 Facebook 之前,他与 Luis von Ahn 共同创立的验证码。最近,本与美国数字服务公司合作,以改进在联邦政府的技术使用。
数人云今天为大家带来一篇 Ben Maurer 分享的“ Facebook 面对大规模系统工程故障排查实践”,由于内容较多,所以数人云今天只为大家带来上半部分,后续内容会在明天发布!
故障是任何大规模工程系统的一部分。 Facebook 的文化价值之一就是拥抱失败。这可以从挂在门洛帕克总部墙上的海报上得到体现:“如果你无所畏惧,你会怎样?”“天佑勇者。”
为了使 Facebook 的系统在快速变化的情况下保持可靠,专门为其研究了常见的故障模式,并建立抽象理念来解决这些问题。这些理念确保最佳实践应用于的整个基础设施。通过建立工具来诊断问题,并创建一种复盘事故的文化来推动并作出改进,防止未来发生故障。
为什么会发生故障?
虽然每一个故障都有一个独特的故事,但是多数故障都可以归结为少数的原因。
个别机器故障
单个机器通常会遇到一个孤立的故障,不会影响基础设施的其余部分。例如,可能一台机器的硬盘驱动器发生了故障,或者某台机器上的服务遇到了代码中的错误,内存损坏或等。
避免单个机器故障的关键是自动化,自动化工作最好结合已知的故障模式(如硬盘驱动器的 S.M.A.R.T.错误)与未知问题的搜索(例如,通过交换服务器异常缓慢的响应时间)。当自动化发现一个未知问题,手工调查可以帮助开发更好的工具来检测和修复问题。
合理工作负荷的变化
遇到突发状况, Facebook 会改变日常的行为习惯,为基础设施带来挑战。例如,在重要的全球事件中,独特的工作负载可能会以不寻常的方式来考验其中的基础设施。当奥巴马赢得 2008 美国总统大选时, Facebook 页面活跃度刷新了记录。如超级杯或者世界杯这样重大的体育赛事也会引发其发帖数量大大增加。负载测试,包括“灰度发布”即有新功能发布,但是对于使用者不可见,有助于确保新功能能够处理负载。
在这些事件中收集的统计数据常常为系统的设计提供一个独特的视角。通常情况下,重大事件导致用户行为的变化(例如,通过围绕一个特定的对象创建主题活动)。有关这些更改的数据通常指向设计决策,以便在后续事件中允许更平滑的操作。
人为失误
鉴于 Facebook 鼓励工程师“快速行动,打破常规”-如同装饰办公室的另一个海报所示,也许有人会认为,很多错误都是人为造成的。根据数据表明,人为失误是失败的一个因素。图 1 涵盖了严重到足以被认为违反了 SLA (服务水平协议)的事件的时间节点数据。由于目标是很严格的,所以对网站用户而言大多数事件是轻微的,不明显的。图 1a 显示事件在星期六和星期日发生的概率大幅减少,然而也不会影响网站流量。图 1b 显示 6 个月的时间只有两周没有事件:包括圣诞节的一周和员工写互评的一周。
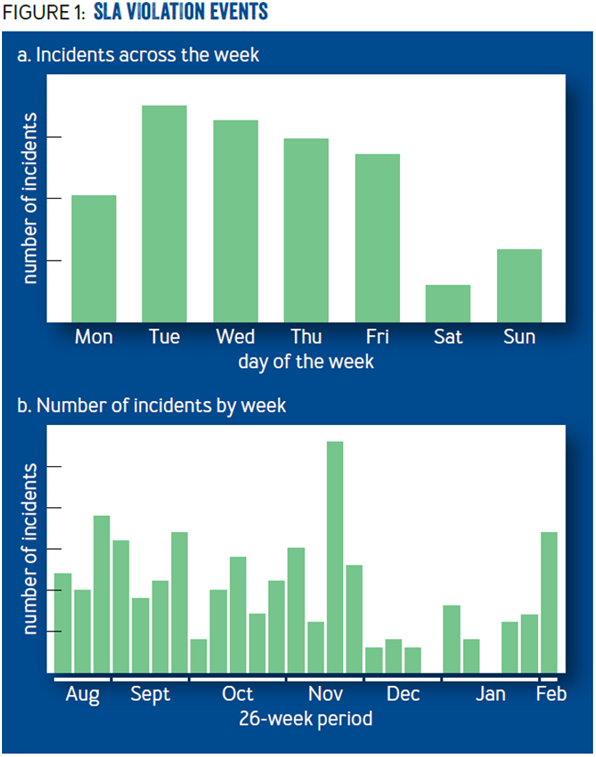
这两个数据似乎表明,当 Facebook 的员工因为忙于其它事情(如周末、节假日以及员工考核等)而没有积极去改变基础设施的时候,网站的可靠性反而处于一个比较高的水平。导致我们相信这不是因为 Facebook 员工过于粗心,而是证明了基础设施在很大程度上是对非人为的错误进行自我修复,如机器故障。
三种容易导致事故的原因
虽然事故有不同的产生原因,但是通过总结发现,有三种常见的原因会使故障扩大并成为大规模的问题。对于每一个成因,都应制定相应的预防措施,以减轻大规模事故。
快速部署配置更改
配置系统往往被设计为能在全球范围内迅速复制更改。 Rapid 配置更改是一个功能强大的工具,可以让工程师快速管理新产品的推出或调整设置。然而,快速配置也意味着当配置不当时会快速引发故障。我们采取了一些方法来防止配置更改导致故障。
- 让每个人都使用一个通用的配置系统
使用通用配置系统可以确保程序和工具适用于所有类型的配置。在 Facebook ,我们发现团队有时会试图以一次性的方式来进行配置。避免使用这种方式而采用一种统一的方式来进行配置,从而使配置系统成为一种提高站点可靠性的衡量方法。
- 静态验证配置更改
许多配置系统允许松散类型的配置,如 JSON 结构。这些类型的配置很容易使工程师犯一些低级错误,例如敲错字段,如果这个字段是必须使用整数的字符串。对于这种类型的错误最好的办法就是使用静态验证。一个结构化的格式(例如,在 Facebook 使用的 Thrift )可以提供最基本的验证。然而,编写验证程序来验证更详细的要求也是合理的。
- 运行一个 Canary
首先将配置部署到服务的小范围,可以防止灾难性的更改。一个 Canary 可以采取多种形式。最明显的是 A / B 测试,如只对百分之一的用户推出一个新的配置。多个 A / B 测试可以同时运行,并且可以使用数据随时间进度来跟踪度量。
然而,对于可靠性的目的, A / B 测试不满足我们的所有需求。一个更改部署给少数用户,但导致了服务器崩溃或内存耗尽的变化,显然会产生超出测试的有限用户的影响。 A / B 测试也费时。工程师们常常希望在没有使用 A / B 测试的情况下推出一些微小的变化。为此, Facebook 基础设施自动测试新配置的一小部分服务器。例如,如果我们希望部署一个新的 A / B 测试给百分之一的用户,首先部署测试在仅影响很少量服务器的那部分用户,在一个很短的时间内监测这些服务器,以确保他们不会崩溃或有其他很明显的问题。这种机制提供了一个适用于所有变更的基本的“健全检查”以确保它们不会造成大面积的故障。
- 保持良好的配置
Facebook 的配置系统的设计是尽量确保当更新带来故障时保持良好的配置。开发人员希望创建的配置系统当接收到无效的更新配置时会崩溃。喜欢在这些类型的情况下保留旧的配置,并向系统操作员发出警报,说明该配置无法更新。继续运行旧有的配置通常优于将错误返回给用户。
- 使它容易恢复
有时,尽管尽了最大努力,部署的配置依然有问题,快速查找和恢复是解决这类问题的关键,配置系统是由版本控制,这使得系统很容易恢复。
核心服务的硬依赖
开发者通常默认配置管理,服务发现,存储系统等核心业务永远不会发生故障。可是,这些核心业务的轻微故障都会引起大面积的事故发生。
- 核心服务的缓存数据
依赖于这些类型的服务通常是不必要的,可以通过缓存数据的方式,以此保证其中一个系统短暂性中断,而其它服务依旧继续运行。
- 提供硬化的 API 使用核心服务
核心服务是最好的补充公共库,遵循最佳实践来使用这些核心服务。例如,库可以提供良好的 api 来管理缓存或处理故障。
- 运行的消防演习
你可能认为能够在核心服务中断中生存下来,在尝试之前,你永远不会知道。对于这些类型的中断,我们不得不开发系统的消防演习,从故障注入系统应用到单个服务器中,以此手动触发整个数据中心的中断。
增加延迟和资源耗尽
一些故障导致服务的延迟增加到客户端。这种增加的延迟可能很少(例如,考虑到一个人的配置错误,但是依旧服务的能力导致 CPU 使用量增加),还有就是,它可能是无限的(一个服务线程服务响应陷入瘫痪)。而少量的延迟可以很容易地解决由 Facebook 的基础设施、大量的延迟会导致全面故障。几乎所有的服务对未完成请求的数量都有限制,这个限制可能是由于每个请求服务线程数量有限,也可能是由于基于故障服务中的内存有限。如果一个服务面临大量的延迟,那么调用它的服务将耗尽他们的资源。这种故障会通过许多层面进入系统服务中,导致系统故障的发生。
资源枯竭是一个极具破坏性的故障模式,由于它允许服务请求的子集用于导致失败的所有请求失败。例如,一个服务调用只推出 1%的用户对新的实验服务,通常要求这个实验服务需要 1 毫秒,但由于在新的服务失败的请求需要 1 秒,所以 1%的用户使用这项新服务请求可能会消耗太多的线程,其他 99 %用户就不能运行此线程。 如今,我们已经发现了一些技术,可以避免这种类型的积累与较低的误报率。
- 控制延迟
在分析以往的事故延迟中,我们发现许多最糟糕的故障涉及大量队列等待处理的请求。有问题的服务有一个资源限制(如活动线程或内存的数量)和将缓冲请求以保持低于限制使用的请求。由于服务无法跟上传入请求的速度,队列会变得越来越大,直到它突破了应用程序定义的限制。为了解决这种情况,我们希望在不影响正常操作和保证可靠性的情况下,来限制队列的大小。我们研究了一个很相似的 bufferbloat ,在保证可靠性的同时,使用队列从而不会造成过度延迟。尝试了一种 codel1 (延时)控制算法:
onNewRequest(req, queue):
if(queue.lastEmptyTime() < (now - N seconds)) {
timeout = M ms
} else {
timeout = N seconds;
}
queue.enqueue(req, timeout)
在该算法中,如果服务不能在最后 N 毫秒内清空队列,则队列中花费的时间仅限于 M 毫秒。如果服务能够在最后 N 毫秒内完成清空队列,则队列中所花费的时间仅限于 N 毫秒。该算法避免站在队列(由于 lastEmptyTime 将在遥远的过去,导致 anM-ms 排队超时),一次达到短时间的排队对于可靠性的目的。虽然它似乎有悖常理,请求时间较短,这个过程允许的迅速丢弃服务,而不是建立在系统无法跟上传入请求的服务。短的超时可确保服务器总是处在工作的状态,而不是空闲。
该算法的一个吸引人的特性是, M 和 N 的值往往不需要调整。解决排队问题的其他方法,如在队列中设置项目的数量或设置队列的超时时间的限制,需要在每个服务基础上进行调整。我们已经发现, M 和 100 毫秒的值是 5 毫秒,它可以很好的用于 N 中。 Facebook 的开源码 library5 提供的算法是由 thrift4 框架实现。
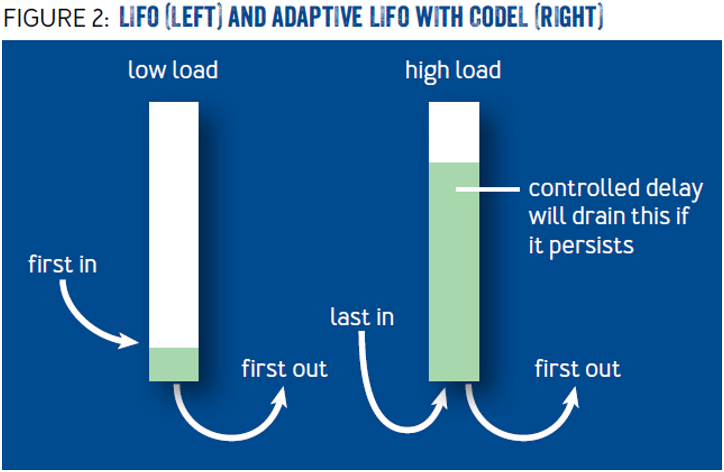
- 自适应后进先出(后进先出)
大多数服务进程队列 FIFO (先进先出)。当处于高额度处理进程中时,先进命令明显已经运行了很长时间,以至于用户可能已经中止了生成请求的操作。当处理先进申请命令时,相比之下这种刚刚抵达的请求命令,首先会消耗少许可能益于用户的请求命令,服务进程请求程序使用的是应后进先出的方式。在正常工作条件下,要求按照先进先出的顺序进行处理,但是当一个队列正要开始成形时,服务器会切换为 LIFO 模式,这时, LIFO 和 CoDel 就可以很好的结合在一起,如图 2 所示。 CoDel 超时设置时,阻止长的计算机程序队列增长,然后具有适应性的先出后进命令在计算机程序队列设置新的请求模式,然后在数字信号编码器的作用下,他们两个能够发挥最大化的作用。 HHVM3 , Facebook 的 PHP 运行时,自适应后进先出法的算法得以实现。
- 并发控制
无论是编码和自适应的后进先出法都在服务器端运行。服务器通常是执行延迟的最好的措施——服务器更倾向于大量的客户同时能够拥有更多的客户信息。然而,有些故障是如此严重,以至于服务器端控件无法启动。为此,我们在客户端实施一种权宜之计。每个客户端会跟踪每个服务器所未完成的出站请求数量。当发送新请求时,如果对该服务的未执行请求的数目超过可配置的数字,则该请求将立即标记为错误。这种机制可防止单个服务垄断其客户端的资源。
以上内容是数人云今天为大家带来的“ Facebook 面对大规模系统工程故障排查实践”的上半部分,其中主要涵盖导致故障的原因、以及可以使用一个通用的系统等相关内容,希望可以对大家有所帮助~明天还会为大家带来最终的解决方案哟,敬请期待~
作者: Ben Maurer
原文: Fail at Scale Reliability in the face of rapid change
