
这是一个创建于 1585 天前的主题,其中的信息可能已经有所发展或是发生改变。
作者介绍
孙旭,腾讯云高级工程师。10 年数据库内核研发经验,熟悉 PostgreSQL、Teradata 数据库内核,熟悉数据库的查询优化、执行、事务并发以及存储等子系统;对分布式数据库有深入的研究和研发经验。目前在腾讯云从事 CynosDB 数据库研发工作。
一、导语
数据库查询处理( Query Processing )是数据库比较核心的技术,也是距离用户最近的子系统。数据库系统在除了实现事务的隔离界别外,还需要在 SQL 上做到一定程度的兼容,因为数据库本身就是在做查询处理,很多的内核模块工作都是为了支持这个功能。本文将简要介绍一下 PostgreSQL 的查询处理过程。
二、关系代数与 SQL (结构化查询语言)
大家在学校学到的可能更多的是关系代数( Relational Algebra ),它定义了一组在关系( Relation )上进行操作的操作符。关系代数的操作数是关系(即,数据库中的二维表),其结果也是关系。操作符包含如下几类:
- 集合操作符:交,并,差;
- 过滤 /投影;
- 连接;
- 别名( alias );
- 一些扩展的操作符,例如:分组,去重,Aggregate。
除了关系代数,还有一种描述二维关系表的操作方法:DataLog ( Database Logic )。这种方式相对来说比较强大,关系代数的操作符都可以用它来表述,但是有些关系的操作是关系代数表示不了的,只能用 DataLog 来表述,比如:递归查询。
直接使用关系代数对数据库操作比较晦涩,难度比较高,因此,今天的商业数据库都实现了一种更高级的查询语言——SQL ( Structured Query Language ),在表达上更加简洁易懂,也更容易学习。
实际上,在数据库系统内部,SQL 语句也是被转化成对应关系代数的操作符,然后再进行处理,只是这些工作对最终用户来说是不可见的。其实,关系型数据库直接的“本地语言”是关系代数,SQL 语言只是人类与关系数据库进行交流的“更加便捷的”桥梁。
可能大家有疑问,为何使用 SQL 作为交流桥梁,而不是用 C、Java 或者 Python 作为数据库的查询语言?
因为一个较短的 SQL 可以完成千百行 C 或者 Java 的工作,特别是在访问一些层次化的数据模型(例如:Oracle 的层次查询,一条语句可以把层次结构输出出来; PostgreSQL 的 WITH-RECURSIVE 语句也可以完成类似的功能)。
更加重要的是,数据库内核在实现 SQL 查询的时候,可以对 SQL 进行特定的优化,产生更加有效的访问方法,这些都是高级语言不太可能具备的功能。
三、PostgreSQL 查询处理流程
从用户在客户端发送一条 SQL 语句,经过网络传输给 PostgreSQL 进行处理、执行,其流程经过如下几个步骤:
1、语法分析
SQL 字符串可以认为是一个大的正则式,语法分析来检查这个大的“正则式”是否 match 定义好的规则。
在 PostgreSQL 中,pg_parse_query 是语法分析的入口函数,实际上由 scan.l ( Flex 文件)以及 gram.y ( Bison 文件)完成语法检查。
scan.l 是词法分析,将输入 SQL 分解一个个的 Token,输入到 gram.y 中进行规则匹配。gram.y 中定义了所有 SQL 类型的语法规则以及操作符的优先级和结合律,例如,下段代码定义了操作符的优先级和结合规则:

下段代码定了语法规则:

语法分析结束后,以查询( SELECT )为例,返回的结构体是 SelectStmt,它会作为作为语义分析模块的输入。SelectStmt 保存了 SQL 语句中的各个语法子部分,例如:from 子句,投影列,group 子句等,从其定义可以看出更多细节:

2、语法检查
parse_analyze()函数是这一步的入口函数,根据不同的语句类型调用 transformXXXXStmt()函数进行分析处理。对于 SelectStmt,调用的 transformSelectStmt(),对于 DeleteStmt 调用 transformDeleteStmt()。在这一步将会:
- 检查表是否存在,列是否合法,将表、排序列、投影列等转化为内部对象 ID ;
- SQL 语义是否正确合法。
比如:Aggregate 函数不能用在 WHERE 中。如下查询:
select 1 from x where max(x2) > 1;
调整聚集函数在适当的层次中计算,如下查询:
select (select max(x.x2) from y) from x;
max(x.x2)在 SQL 语义上应该是在最外层查询中计算,而不是将 x.x2 传入到内层子查询,在内层子查询中计算 Aggregate 函数 max()的值。而对于如下查询:
select (select max(x.x2+y.x2) from y) from x;
max(x.x2+y.x2)是在内层子查询中被计算,而不是作为外层查询的 Aggregate 函数。
经过语义检查,会将 SelectStmt 变形为 Query 结构,作为查询重写的输入。Query 结构包含的部分与 SelectStmt 类似,只不过内容更加丰富:
- 保存的都是数据库内部的对象信息;
- 一些 flag 标记,表明是否包含:Aggregate 函数、窗口函数、SubLink 子查询等;
- 确定了表达式所在的 Query 层次。
之前提到过,数据库内核处理 SQL 时都是转化成关系代数相关的元素,这个在 Query 结构体中可以看到这点:

例如:
- 关系代数的投影是:targetList ;
- 关系代数的过滤 /join 是:jointree ;
- 关系代数的 Aggregate 是:targetList ;
- 关系代数的分组:groupClause ;
- 关系代数的 sort 是:sortClause。
后续所有的工作都是基于上面的元素进行。
3、查询重写
根据用户定义的规则对查询进行重写,实际是对 Query 结构里面的成员进行修改或替换,这些规则可以使用 CREATE RULE 创建。如果用户在查询对应的表上没有规则,此步跳过。
4、查询优化
查询优化是比较复杂子系统,通常称这个模块是“优化器”,也用来衡量数据库系统优秀的一个方面。在数据库领域另一个复杂的子系统是事务处理,这里也不做展开。
PostgreSQL 在这一步的输入是 Query 对象,入口函数是 planner(),输出查询计划( Query Plan ),查询计划是指导查询如何被执行以及用何种方法执行的一种结构,通常是树形结构。
优化器做的主要工作就是对 Query 结构的各个语法部分,选择较优的执行算法,输出较优的执行计划。在 PostgreSQL 中,通常分成如下几步:
1 )子查询处理
在 PostgreSQL 内部有 2 类的子查询:一种在 from 语句后面称为 SubQuery,另一种在作为表达式的一部分,可以出现在 targetList,过滤条件,连接条件中,称为 sub-link。
这两种都可以统称为 Sub-Select,而优化器在这一步会进行 Sub-Select Elimination:将子查询上拉到顶层查询,消除子查询。
这样做可以减少查询层数,增加上层表的个数,从而增加 join 顺序的搜索空间,有助于找到较优的连接顺序。以 sub-link 为例,说明一下这个步骤的工作。对于查询:
select * from x where x.x2 in (select y.x2 from y);
PostgreSQL 在这步可以将 IN 语句转化成 Semi-Join,原来的 O(m*n)的查找算法简化为 O(1)HASH-JOIN 算法。
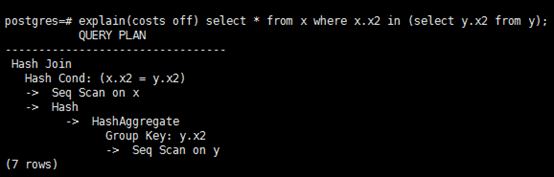
这里执行计划并没有使用 Hash Semi-Join,是因为 inner plantree 用了 group hashagg 进行了去重,所以原来的 Semi-Join 可以进一步优化为 Hash Join,这种优化进一步扩大了 Join 顺序搜索空间。
2 )执行表达式预处理
在这一步,会将 targetList,过滤条件等列修改为对基表的引用;对表达式里面的 SubLink 递归调用优化器优先进行优化;计算表达式里面的常量表达式等。
3 )移除无用的 GROUP BY 列
如果内核可以确定 GROUP BY 中的一些属性集合 Y 函数依赖于其他属性集合 X,那么可以删除 GROUP BY 中的属性集合 Y。函数依赖检查工作由 check_functional_grouping 完成。这样可以减少分组计算代价。
4 ) Reduce outer join
将某些 OUTER JOIN 转化为 INNER JOIN。
5 )选择优化的 Join 顺序
在这一步完成主要完成:条件的下推,基于连接条件生成等价类,以及通过动态规划选择较优的 JOIN 顺序。从整体来看,JOIN 顺序的选择是 Condition-Driven,而不是完全的对所有的表进行排列组合求解。例如对于查询:
select * from r, p, q where r1 = (p1+q1) and r2=q2;
通常我们可能认为 r 和 q 在 r2=q2 的条件进行连接,然后与 p 在 r1 = (p1+q1)上进行连接;但是 PostgreSQL 内核在也会做这样的尝试:将 p 和 q 进行 product join,再与 r 在条件 r1 = (p1+q1) and r2=q2;进行连接,p 和 q 之所以可以连接完全是由 r1 = (p1+q1)决定的。
6 )其他子句优化处理
做完 Join Plan 之后,再针对 GROUP BY、Aggregate、ORDER BY、LIMIT 等子句进行处理。以 GROUP BY 为例,在 PostgreSQL 内部,实现 GROUP BY 的有 2 个算法:Sort Group By 以及 HashAgg Group By,通过函数 cost_group 以及 cost_agg 分别来计算二者代价,选择较优的算法执行。
完成这些这些步骤后,调用 set_plan_references()以及 SS_finalize_plan()函数最后处理参数和变量引用后,就可以输出最终的查询计划( Execution Query Plan )了。查询计划由很多节点组成:投影、扫描、连接、Aggregate、GROUP BY、排序等,从这些名称也可以看出他们就是关系代数的操作符,它们会被传给查询执行组件进行执行。如下查询计划示例:
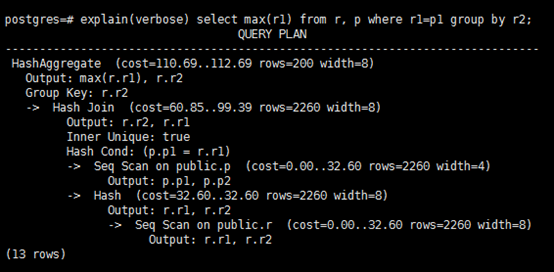
5、查询执行
这是查询处理的最后一步,将优化器输出的执行计划,进行初始化、执行。查询执行子系统我们一般称为执行器。执行过程有 ExecutorStart、ExecutorRun、ExecutorFinish 这三个入口函数,分别完成对查询计划的初始化,执行,以及清理。在这个过程中会访问数据库的其他子系统,如:事务系统、存储系统、日志系统。
以上就是在 PostgreSQL 内核中对一个查询处理的整个生命周期,基本可以了解到一个 SQL 字符串在数据库内核中是如何一步步被解析,直到到执行的基本过程。
上文中描述的一些方法和理论不仅仅在 PostgreSQL 数据库有效,也可以推导到其他数据库系统中。
四、PostgreSQL 执行器算法之 SeqScan
上文讲述了数据库内核中查询处理的基本流程,现在我们先展开讲述执行器算法。
数据库的执行器包含了很多个算子的执行算法,比较简单的一种就是 SeqScan,就是从按照顺序(一般是存储顺序)对表进行扫描。
1、页面结构
PostgreSQL 页面存储与大多数数据库的类似,包含:页面头,ItemId 数组,以及 Item (元组),布局如下:
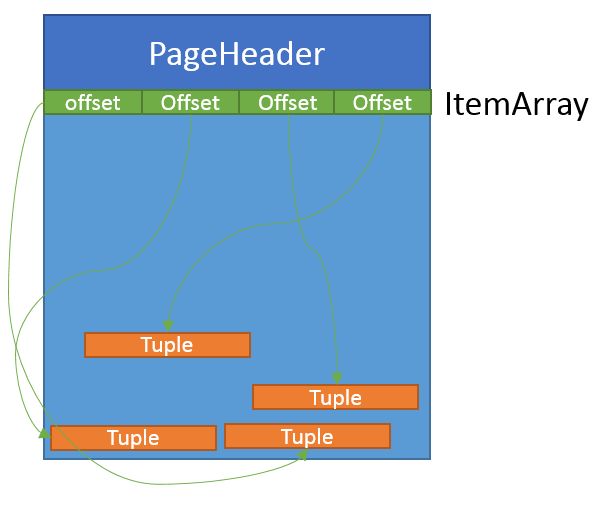
其中 PageHeader 包含了页面 LSN,ItemId 数组最后一个元素的页面偏移( pd_lower ),第一条元组在页面内偏移( pd_upper ),以及其他字段。
2、顺序扫描算法
PostgreSQL 的顺序扫描的入口函数是 SeqNext,每次执行这个函数会返回一条元组,主要工作是由 heapgettup:
1 )初始化扫描过程
初始化扫描过程就是设置 HeapScanDesc 对象,主要设置初始扫描的页面,一般从 0 号页面的第一个元组开始,即 scan->rs_startblock 是 0。
在 PostgreSQL 的扫描过程有一个优化,即 sync_scan,这个特性允许当前的扫描从表的中间页面开始扫描,这个页面是其他扫描进程填写到共享内存,由 ss_report_location 完成,代表这些页面刚刚被访问过,如果当前扫描从这些页面开始,那么可以直接在内存中访问到,从而减少存储读取页面的 IO 次数,提升性能。
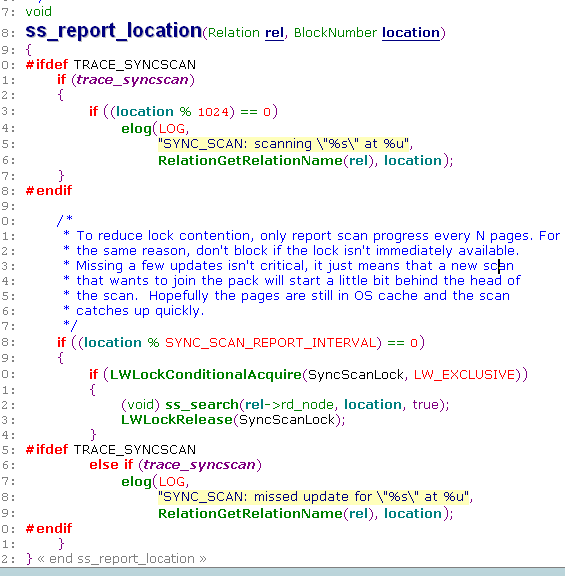
每次更新表的 sync start page 时,需要遍历整个 list。为了减少这个 list 的访问,每隔 SYNC_SCAN_REPORT_INTERVAL 个页面才去更新 list,这个数值是 128 * 1024 / BLCKSZ。
2 )读取页面进行扫描
按照页面结构扫描页面。首先读取页面头( PageHeaderData )的 pd_linp 成员,这是一个 Offset 数组( ItemIdData ),记录了元组在页面上的偏移( lp_off )。

后续的主要逻辑是遍历 pd_linp 数组,通过 offset+page 地址获取到元组内存地址。然后对元组做可见性判断。逻辑如下:

HeapTupleSatisfiesVisibility 进行元组可见性判断,PostgreSQL 是 MVCC 实现的事务隔离,这个函数就是 MVCC 的入口逻辑。
3 )读取下一个页面继续进行扫描
继续读取后续页面进行扫描。
所有的扫描状态保存在 HeapScanDesc,下次扫描的时候,可以从上次的状态开始。
江湖召集令
9 月 27 日-11 月 6 日,腾讯云数据库王者挑战赛(点击查看详情) 等你挑战!花几分钟参加比赛免费将☟☟抱回家!
- MacBook/iPhone 11/AirPods
- 25 台 Kindle
- 8 万元腾讯云创业基金
- MySQL 之父 Michael Widenius 面对面交流
拥有与殿堂级大神的合影和亲笔签名书籍的你,
能让隔壁码农羡慕到流泪!
转发下方海报参与活动可以获得腾讯公仔和腾讯云数据库购买直抵代金券,详情请添加海报上机器人二维码咨询。
比赛详情&报名入口
请扫下方二维码

点击优惠购买腾讯自研数据库 CynosDB
目前尚无回复